Many background jobs call an external system on behalf of separate accounts, tenants, or installations. The external system allows parallel calls across different accounts, but it does not allow two calls for the same account to run at the same time.
That is not a global rate limit. It is concurrency by key: the key might be
account_id, tenant_id, or another argument that identifies the shared
quota or state boundary.
You want the worker pool busy across many accounts, while each account stays serial. Without that guard, two workers eventually pick up work for the same account in parallel. The external system may throttle the account, reject the second call, or leave you with a partial update to reconcile.
The usual fixes are external locks, one queue per account, or retry/backoff logic around every call. They can work, but they add another coordination layer to the job system.
Pynenc’s orchestrator already tracks running invocations and their arguments.
With running_concurrency=KEYS and key_arguments=("account_id",), it can
enforce one in-flight invocation per account key while still running different
accounts in parallel. reroute_on_concurrency_control decides whether blocked
work waits or is dropped, and registration_concurrency=KEYS can collapse
duplicate work before a worker sees it.
Full sample: samples/concurrency_demo.
The demo
Four tiny files, each doing one thing:
concurrency_demo/
├── api_server.py # tiny HTTP app: pretends to be the external provider
├── tasks.py # PynencBuilder app + 4 tasks (the whole story)
├── enqueue.py # CLI: enqueue one scenario, print results
└── sample.py # one-command demo: boots api+worker, runs all scenarios
The “external provider” is a small HTTP app that holds an account in flight for 0.4 seconds per call and records a collision whenever a second request arrives while the first is still in flight. In a real integration, that collision could be a 429, a rejected write, or an inconsistent refresh:
# api_server.py — the part that matters
@app.post("/call/{account_id}/{op}")
async def call(account_id: str, op: str, hold: float = HOLD_SECONDS) -> dict[str, str]:
async with lock:
acc = accounts[account_id]
acc.calls += 1
collided = acc.in_flight > 0
acc.collisions += int(collided)
acc.in_flight += 1
print(f" [{'COLLISION' if collided else 'ok '}] {account_id:<8} {op}", flush=True)
await asyncio.sleep(hold)
async with lock:
accounts[account_id].in_flight -= 1
return {"outcome": "collision" if collided else "ok"}
The pynenc app and the four tasks fit on one screen. The whole pynenc
configuration — SQLite backend, in-process thread runner, logging — sits
fluently in tasks.py next to the tasks that use it:
# tasks.py
import os
import httpx
from pynenc import PynencBuilder
from pynenc.conf.config_task import ConcurrencyControlType as Mode
API_URL = "http://127.0.0.1:8765"
app = (
PynencBuilder()
.app_id("concurrency_demo")
.sqlite("concurrency_demo.db")
.thread_runner(min_threads=1, max_threads=8)
.logging_stream("stdout")
.logging_level(os.environ.get("DEMO_LOG_LEVEL", "info"))
.max_pending_seconds(3.0)
.build()
)
def _hit(account_id: str, op: str, hold: float | None = None) -> str:
params = {"hold": hold} if hold is not None else None
r = httpx.post(f"{API_URL}/call/{account_id}/{op}", params=params, timeout=10.0)
r.raise_for_status()
return r.json()["outcome"]
@app.task
def call_unsafe(account_id: str, op: str) -> str:
return _hit(account_id, op)
@app.task(
running_concurrency=Mode.KEYS,
key_arguments=("account_id",),
reroute_on_concurrency_control=True,
)
def call_keyed(account_id: str, op: str) -> str:
return _hit(account_id, op)
@app.task(
running_concurrency=Mode.KEYS,
key_arguments=("account_id",),
reroute_on_concurrency_control=False,
)
def call_keyed_drop(account_id: str, op: str) -> str:
return _hit(account_id, op)
@app.task(
running_concurrency=Mode.KEYS,
registration_concurrency=Mode.KEYS,
key_arguments=("account_id",),
reroute_on_concurrency_control=True,
)
def refresh_once(account_id: str) -> str:
return _hit(account_id, "refresh")
How to run it
You can launch the demo two ways. The four-terminal flow is useful when you want to watch the API, the worker, and the pynenc monitor at the same time. The one-command flow boots the API and worker for you and runs every scenario in sequence; it is the path used by CI.
# four terminals — recommended for exploring
uv run uvicorn api_server:app --port 8765 # 1. API
uv run pynenc --app tasks.app runner start # 2. worker
uv run pynenc monitor # 3. monitor (optional) at http://127.0.0.1:8000
uv run python enqueue.py all # 4. enqueue scenarios
# one command — recommended for CI
uv run python sample.py
What the API observes
All four scenarios, end to end, on a single pynmon timeline. Read it left to right: scenario A starts with overlapping calls for the same accounts; B fans out into three account lanes that stay serial per account; C drops blocked work instead of rerouting it; D collapses duplicate refresh requests before a worker ever sees them.
Two pynenc state names appear in the screenshots and logs. REROUTED means
the worker tried to start an invocation, found the account key already busy,
and put the invocation back on the queue. CONCURRENCY_CONTROLLED_FINAL
means the invocation was blocked by the key rule and intentionally finished
without running.

Four scenarios, four stories. Each one below pairs the per-scenario summary, the API server’s collision log, and the matching pynmon timeline.
Scenario A — no concurrency control
The baseline pain. Different provider operations, same account_id key.
The runner can hold up to eight invocations in flight, and it does — most
of the 12 invocations start essentially together. The first call per
account reaches the provider cleanly; everything that overlaps the same
account is recorded as COLLISION — the stand-in for a real 429,
throttle, or inconsistent response.
=== A. unsafe — no concurrency control ===
12 enqueued -> 12 calls, 9 collisions, 1.42s
X acme calls=4 collisions=3
X globex calls=4 collisions=3
X initech calls=4 collisions=3
--- reset @ 11:49:40 A. unsafe — no concurrency control ---
[ok ] acme fetch_profile
[COLLISION] acme list_invoices
[ok ] globex fetch_profile
[COLLISION] acme update_metadata
[COLLISION] acme refresh_usage
[COLLISION] globex refresh_usage
[COLLISION] globex list_invoices
[COLLISION] globex update_metadata
[ok ] initech fetch_profile
[COLLISION] initech list_invoices
[COLLISION] initech refresh_usage
[COLLISION] initech update_metadata
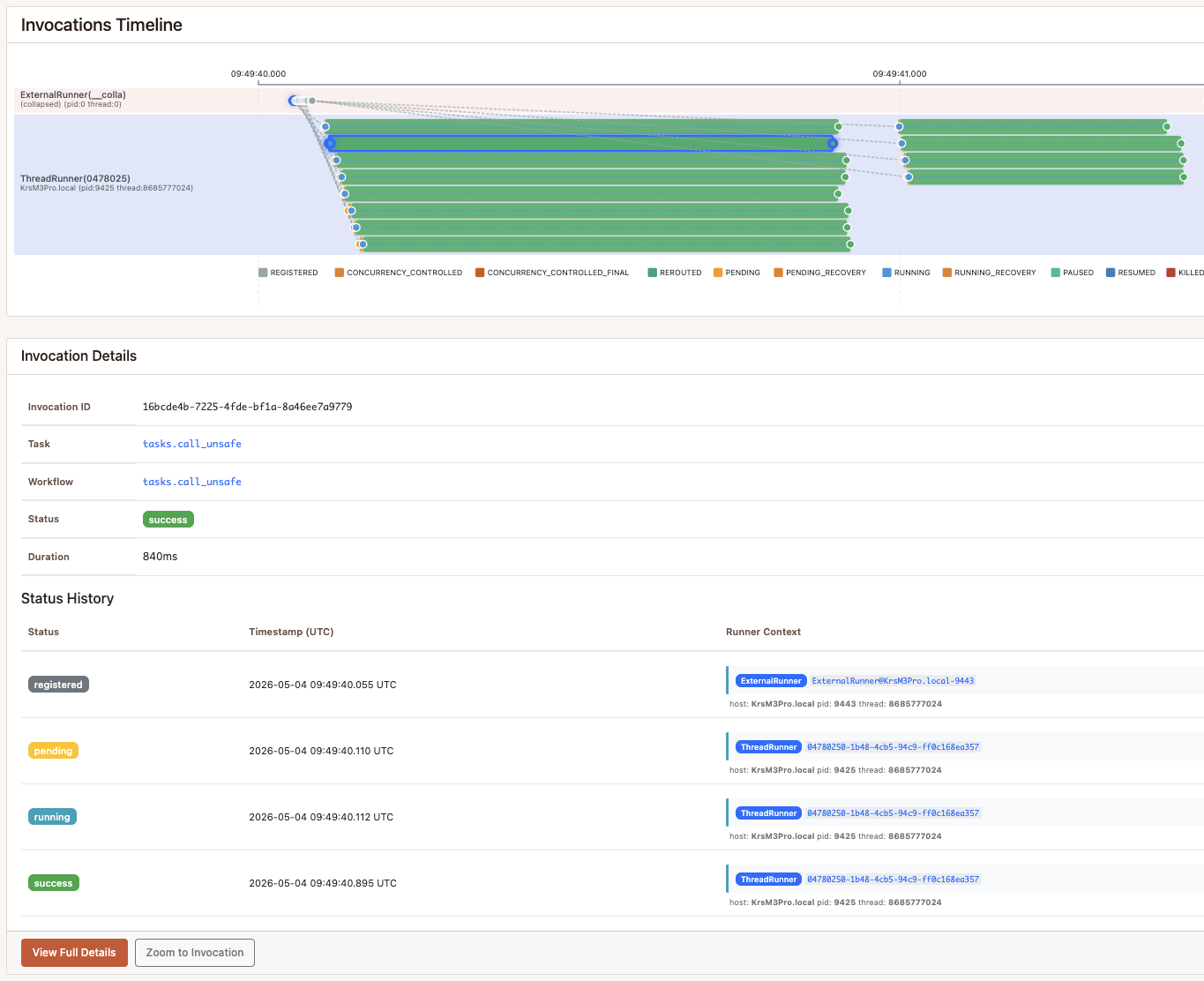
Scenario B — running_concurrency=KEYS, reroute=True
Same 12 calls as A, no collisions. The orchestrator indexes invocation
arguments and refuses to start a second call_keyed while one with the same
account_id is already running. When a worker tries to pick up a blocked
invocation, reroute_on_concurrency_control=True puts it back on the queue
so it can run when the slot frees up. The timeline shows three clean lanes,
one per account, with blocked invocations moving through REROUTED until
they get their turn.
=== B. keyed — running_concurrency=KEYS, reroute=True ===
12 enqueued -> 12 calls, 0 collisions, 2.14s
OK acme calls=4 collisions=0
OK globex calls=4 collisions=0
OK initech calls=4 collisions=0
--- reset @ 11:49:41 B. keyed — running_concurrency=KEYS, reroute=True ---
[ok ] acme fetch_profile
[ok ] globex fetch_profile
[ok ] initech fetch_profile
[ok ] initech list_invoices
[ok ] acme update_metadata
[ok ] globex list_invoices
[ok ] initech refresh_usage
[ok ] globex update_metadata
[ok ] acme refresh_usage
[ok ] globex refresh_usage
[ok ] initech update_metadata
[ok ] acme list_invoices
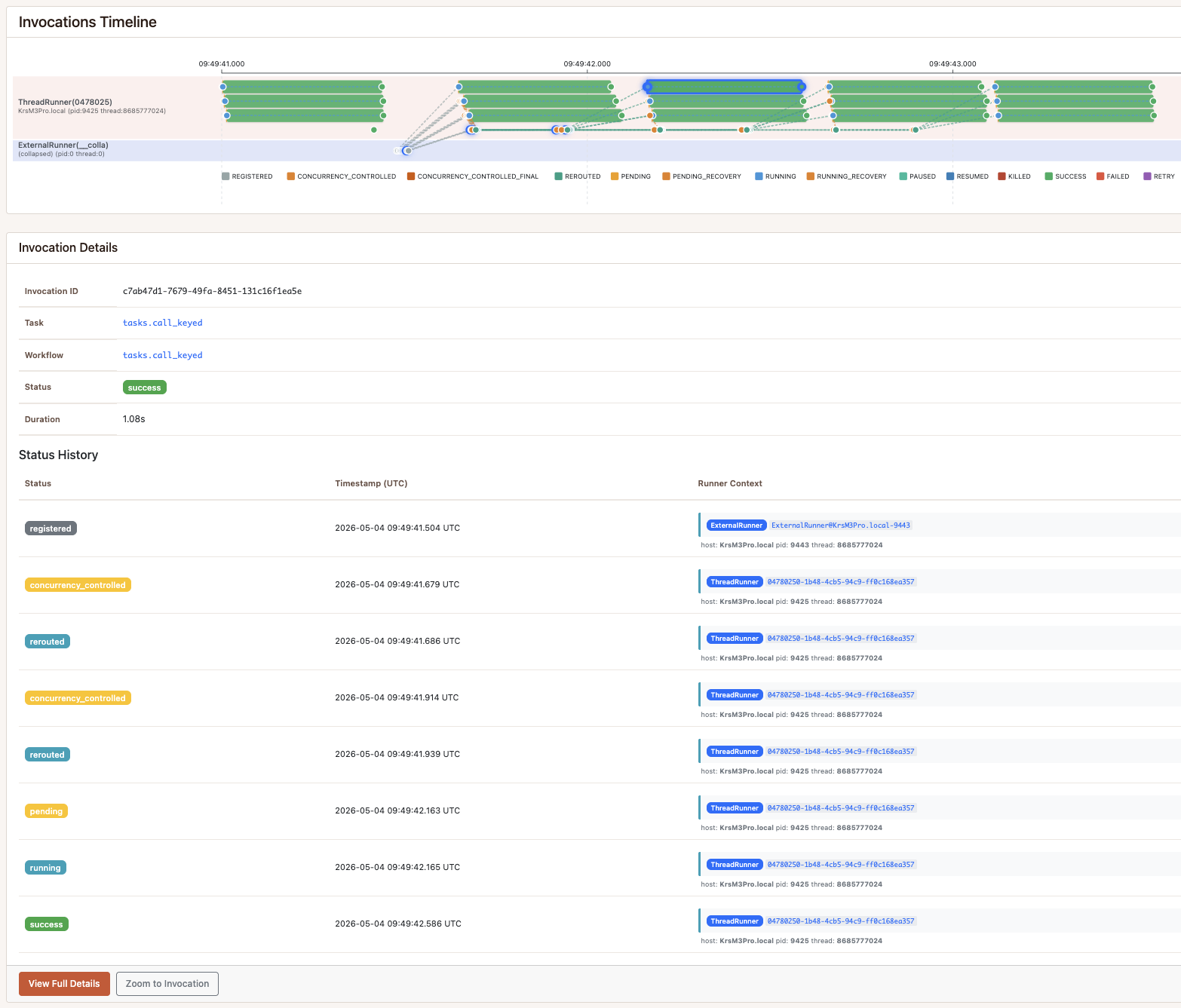
Scenario C — running_concurrency=KEYS, reroute=False
Same guard, opposite policy. reroute_on_concurrency_control=False tells
the orchestrator not to re-queue blocked invocations — they land in
CONCURRENCY_CONTROLLED_FINAL and inv.result raises KeyError. Only
the first invocation per account_id ever reaches the provider; the other
nine are dropped. The timeline ends almost as soon as the first three
invocations finish.
=== C. drop — running_concurrency=KEYS, reroute=False ===
12 enqueued -> 3 calls (9 dropped), 0 collisions, 0.67s
OK acme calls=1 collisions=0
OK globex calls=1 collisions=0
OK initech calls=1 collisions=0
--- reset @ 11:49:43 C. drop — running_concurrency=KEYS, reroute=False ---
[ok ] acme fetch_profile
[ok ] globex fetch_profile
[ok ] initech fetch_profile
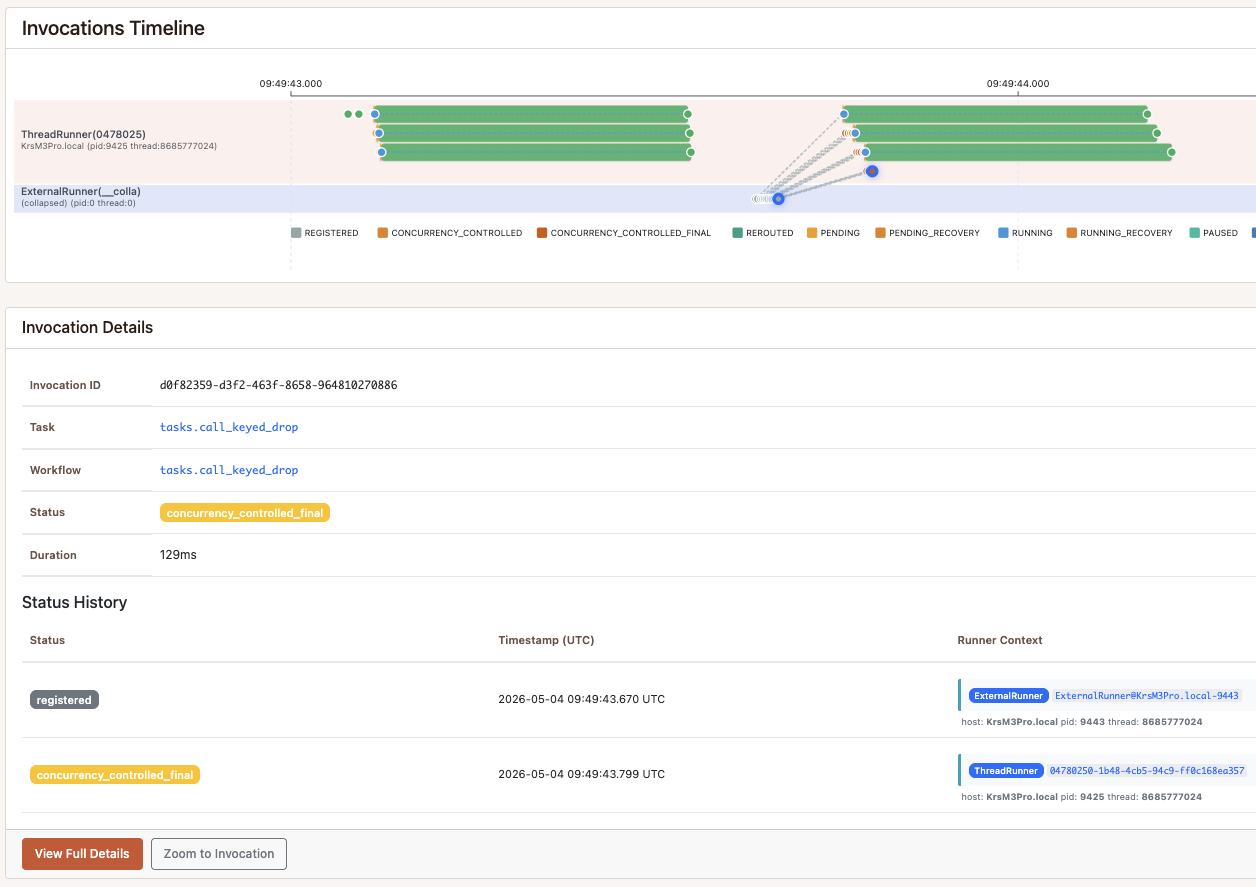
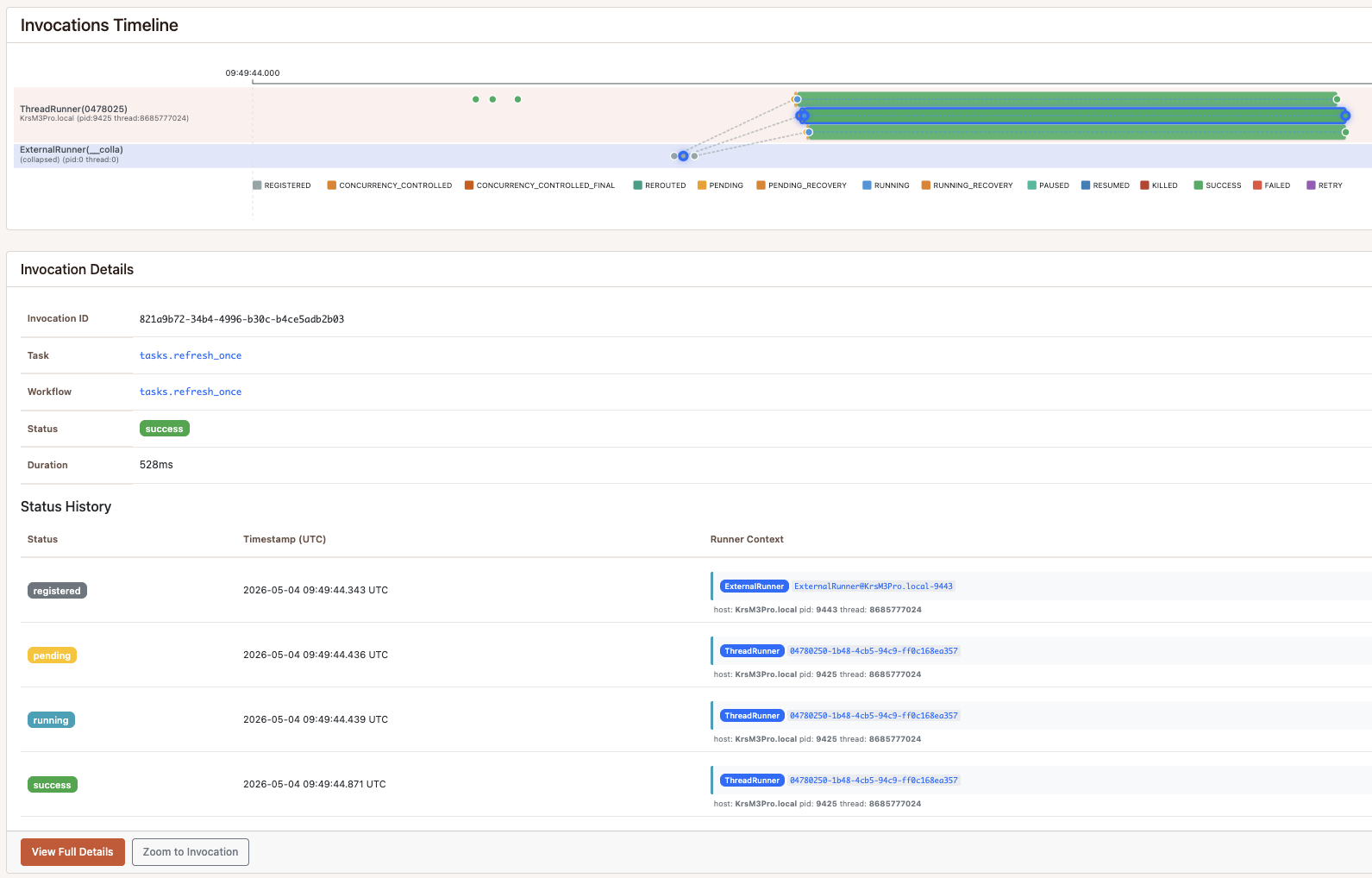
Scenario D — registration_concurrency=KEYS + running_concurrency=KEYS
A different question. registration_concurrency checks at enqueue time:
when refresh request number two for acme arrives, there is already one
registered, so the producer gets back a ReusedInvocation pointing to the
first. 24 logical “please refresh this account” events, eight per account,
collapse to 3 actual API calls before a worker picks them up. The
running_concurrency guard is the safety net for the case where a worker
picks up the first task before all duplicates have registered.
=== D. dedupe — registration + running KEYS ===
24 enqueued -> 3 calls (21 deduped), 0 collisions, 0.57s
OK acme calls=1 collisions=0
OK globex calls=1 collisions=0
OK initech calls=1 collisions=0
--- reset @ 11:49:44 D. dedupe — registration + running KEYS ---
[ok ] acme refresh
[ok ] globex refresh
[ok ] initech refresh
When to reach for which
The pattern applies whenever an argument marks the boundary for shared state or quota. The external system may be a third-party API, an internal service, or a resource that should only be touched by one task at a time for a given key. The system may allow broad parallelism overall, while still requiring serialization for each account, tenant, installation, or resource id.
The two settings cover most of what people reach for an external rate-limiter or a per-tenant lock service for:
running_concurrency=KEYSonaccount_id(ortenant_id, oroauth_installation_id, orclient_token), withreroute=True— when the rule is “no two calls in flight for the same client account”, but you still want all calls to eventually complete. Blocked calls re-queue and retry until a slot opens. Good for distinct operations (op1, op2, op3…) that all need to run.- Same, with
reroute=False— when the rule is “if a call for this account is already running, drop the new one”. Queue depth stays flat; no retry buildup. Good for “trigger a refresh, but if one is already in flight, skip it”. registration_concurrency=KEYS+running_concurrency=KEYSon the same key — when “do this once per client right now” is enough, regardless of how many places triggered it. “Refresh client dashboard”, “rebuild client index”, “regenerate client report”. A noisy internal event bus firing the same refresh 50 times per second is a bug; deduping it before it reaches a worker keeps queue depth honest. The running guard is the safety net: if a worker is fast enough to pick up the first task before all duplicates register, the second flag prevents a parallel run. Together they guarantee exactly one call per account, regardless of timing. Scenario D in the sample.
In production terms, the useful part is that this does not require a separate lock service. The orchestrator already tracks invocations to route work; checking whether a matching key is already running uses that same state.
Simpler scopes when you don’t need keys
This post zooms in on KEYS, but it is one of four scopes. The same two
flags (running_concurrency and registration_concurrency) accept any
value of ConcurrencyControlType:
DISABLED— the default. No concurrency check.TASK— at most one invocation of the task itself in the chosen state, regardless of arguments. “Only one nightly cleanup may run.”ARGUMENTS— at most one invocation per full argument tuple. Two calls with identical arguments collapse; calls that differ in any argument run in parallel. “Don’t run the same export twice.”KEYS— at most one invocation per chosen subset of arguments (key_arguments=(...)). The mode this post is about: serialise on the account key, ignore the operation name.
The scope you pick controls what counts as a duplicate. The flag you put
it on (registration_concurrency vs running_concurrency) controls
when the check happens — at enqueue time or at run time.
Full reference, including how key_arguments interacts with each scope and
the other concurrency knobs, is in the pynenc docs:
Concurrency Control use case.
What’s not in the box yet
Two things people will (correctly) ask for:
- Multi-slot concurrency — “up to 5 in flight per key”, not just 1.
- Time-window rate limits — “100 calls per minute per key”.
Both are on the roadmap. The current primitive - one in-flight invocation per task/key - already covers a common integration problem: systems that allow parallelism across accounts but not overlapping work for the same account. The bigger controls build on the same orchestrator machinery.
How to try it
git clone https://github.com/pynenc/samples
cd samples/concurrency_demo
uv sync
uv run python sample.py
The full sample and README are at
github.com/pynenc/samples/tree/main/concurrency_demo.
The pynenc framework is on PyPI as
pynenc and the source is at
github.com/pynenc/pynenc. Issues, ideas,
and “this would be great if it also did X” comments are welcome.