Most distributed task frameworks give you a queue. Put work in, workers pull it out. That covers the easy half of background processing.
The other half is everything that decides when work runs:
- a job has to run on a schedule
- a job has to run when another job finishes
- a job has to run when another job fails (compensation)
- a job has to run when an external event arrives
- a job has to run only when several of those conditions are true at once
Each one of these is a normal CS or distributed-systems concept: the Observer
pattern, scheduled execution, pub/sub, pipeline composition, the Saga
pattern’s reactive leg, composite predicates. In the average task framework
they end up scattered across a Beat process, callback chains at the call
site, sensors in a DAG file, and a small forest of if/else inside the
task body.
Pynenc’s trigger system tries to keep all of these in one place: a
declaration next to the task that reacts. This post walks through the six
patterns side by side, using the runnable
samples/trigger_demo
sample as the worked example.
A few terms first
A pynenc task is a normal Python function decorated with @app.task.
A trigger is a declaration attached to that decorator describing when
the task should run on its own — without anyone explicitly calling it. The
trigger backend stores those declarations and the runner’s atomic
service tick evaluates them. An invocation is a single execution of a
task; the orchestrator tracks invocation state.
A trigger is built with a small chainable API: on_cron, on_event,
on_status, on_result, on_exception, plus with_logic("and"/"or") and
with_args_* to feed the reacting task’s arguments.
One startup detail matters. Pynenc normally imports a task module when a runner receives the first invocation for a task in that module. A trigger-backed task needs to be known before that first invocation can exist, so its module must be declared explicitly:
[tool.pynenc]
trigger_task_modules = ["tasks"]
The runner imports those modules at startup and registers their trigger conditions for the app-level atomic service. Other task modules remain lazy-loaded.
The example: a tiny news aggregator
The sample defines ten tasks. Together they demonstrate the different coordination styles:
ingest_feed— runs on a cron schedule and on afeed_updatedeventenrich_article— reacts to per-article events emitted byingest_feednotify_subscribers— fires onenrich_articleSUCCESS, but only for thebreaking_newskind (argument filter)alert_editorial— fires whenenrich_articleraisesEnrichmentErrorgenerate_digest— fires wheningest_feedsucceeded and returned more than the digest thresholdarchive_old_content— pure cronpoll_target— one invocation observed by the comparison taskspolling_tasks— repeatedly readspoll_target’s durable statusreactive_tasks— starts frompoll_target’s SUCCESS condition
The whole story fits in tasks.py. No DAG file, no separate scheduler
process, no callback wiring at the call site.
1. Polling vs. reactive (Observer)
The sample starts one poll_target invocation, then compares a tasks polling the result
to a reactive one using pynenc triggering system.
POLL_INTERVAL_SECONDS = 0.3
TARGET_RUN_SECONDS = 0.2
@app.task
def poll_target() -> str:
"""A short task observed by both comparison paths."""
time.sleep(TARGET_RUN_SECONDS)
return "done"
@app.task
def polling_tasks(target: "DistributedInvocation") -> str:
"""Poll durable status until the target succeeds."""
_ = target.result
return "observed"
@app.task(
triggers=TriggerBuilder().on_status(
poll_target, statuses=[InvocationStatus.SUCCESS]
),
)
def reactive_tasks() -> str:
"""Run after pynenc processes the target's SUCCESS condition."""
return "reacted"
reactive_tasks consumes no worker while waiting: pynenc creates it only
after the target’s SUCCESS condition is processed.
polling_tasks would wait until poll_targed succeeds and the result is available.
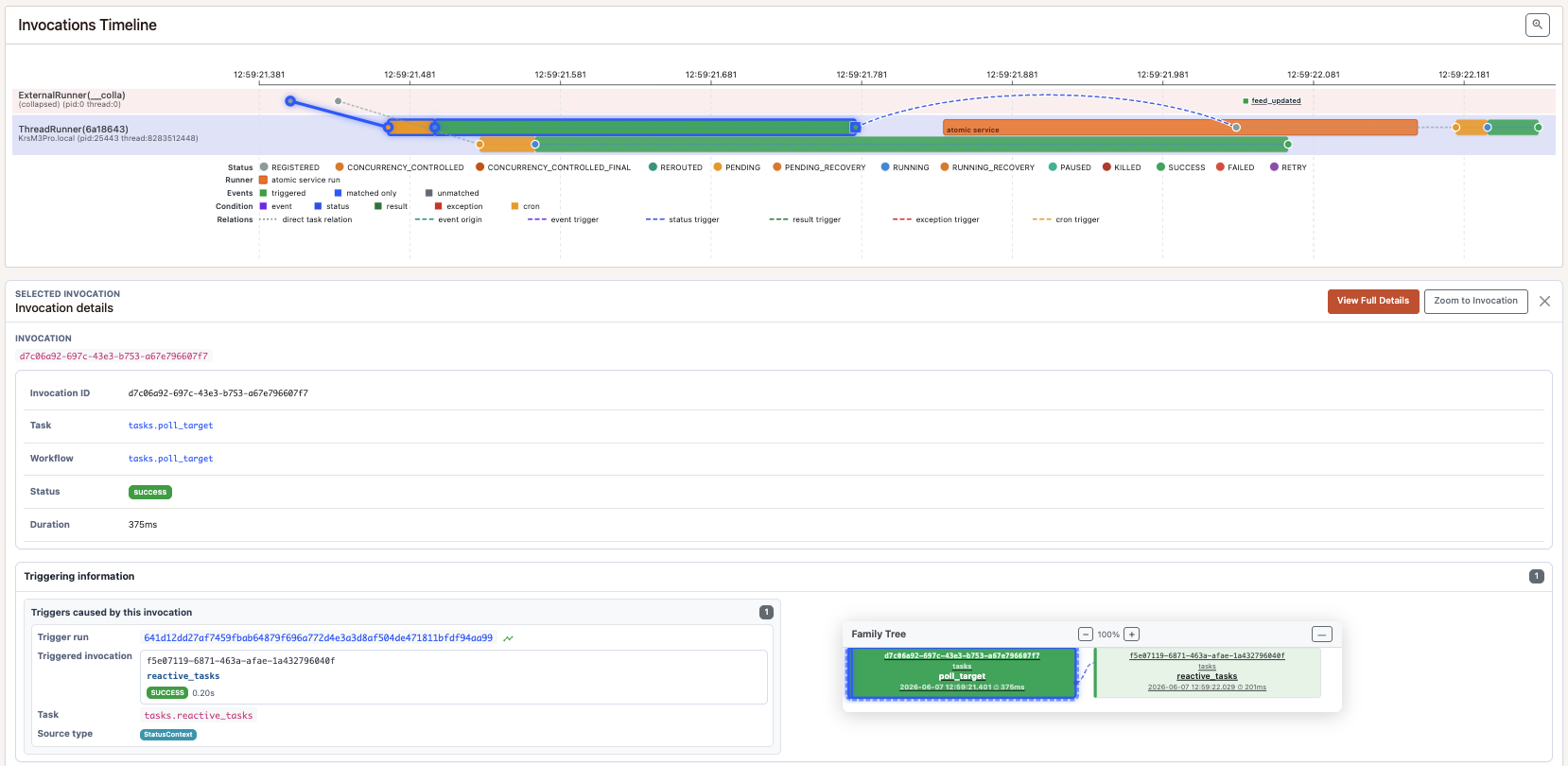
There’s no such thing as a free lunch
Not actively waiting on an invocation does not make the coordination work disappear. Durable state still has to be checked, conditions evaluated, and each reaction claimed and routed once.
Pynenc centralizes that shared work in its atomic service, instead of requiring one polling loop or waiting task per invocation. The sample runs it frequently to keep reactions close together; its coordination details deserve a separate article.
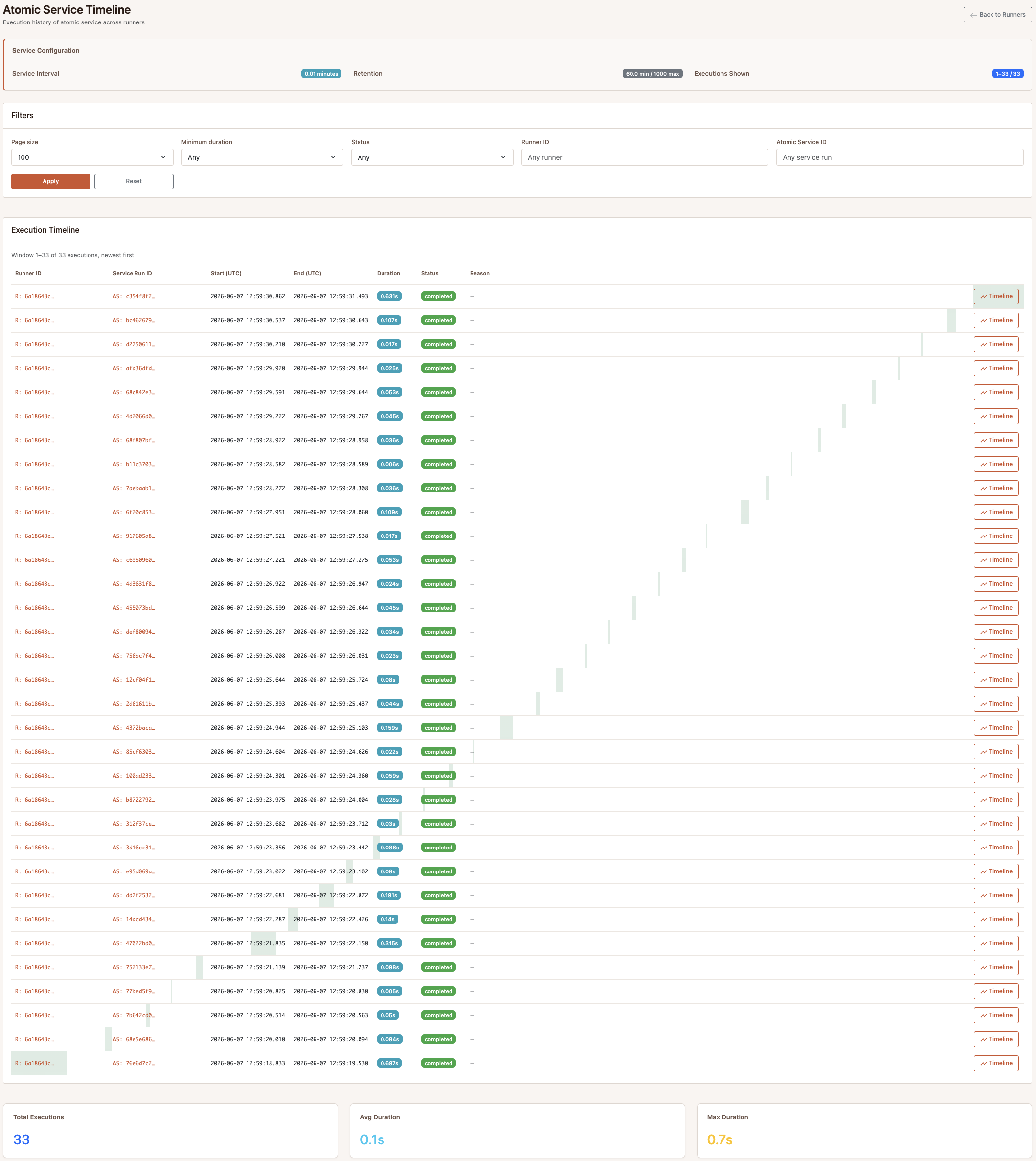
2. Scheduled execution (cron)
TriggerBuilder().on_cron("*/15 * * * *")
No Beat process, no crontab line, no separate scheduler container. The
worker’s atomic service tick evaluates cron conditions during its normal
loop. Cron resolution is one minute, so this is for normal scheduling, not
sub-second timing.
The atomic-service cadence is configurable. This sample runs it more often to keep reactions close together in the timeline; other systems can tune the interval to their latency and coordination requirements.
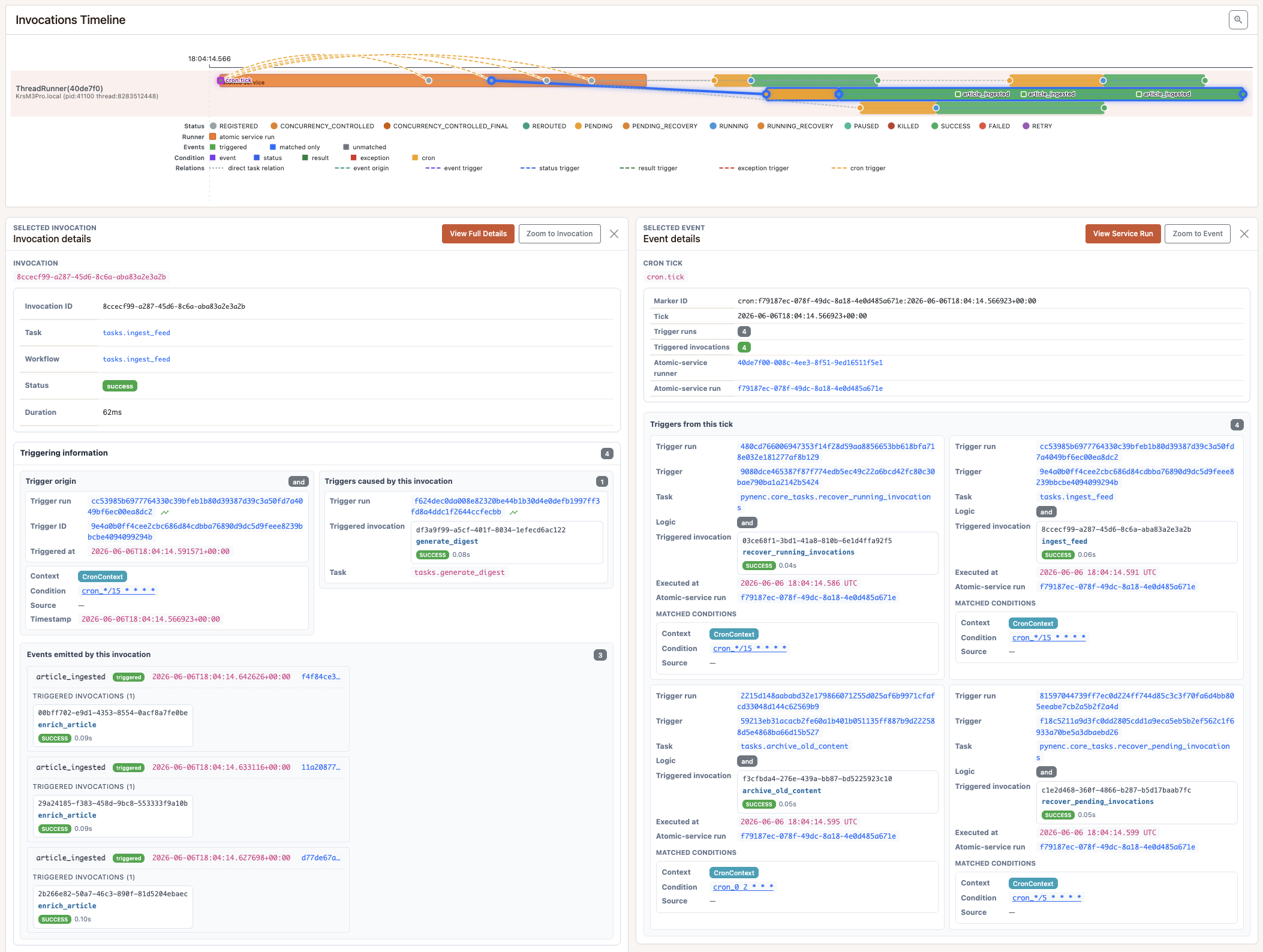
The timeline focuses on this scheduled run. The selected cron tick was handled
by the atomic service and triggered ingest_feed and archive_old_content,
alongside two internal recovery tasks. ingest_feed is selected, highlighting
its path from the cron event to the invocation.
3. Event-driven pub/sub
The producer side:
app.trigger.emit_event("feed_updated", payload={"source": "rss_live", "count": 3})
The consumer side, declared on the reacting task:
def _args_from_feed_event(ctx: EventContext) -> dict:
return {"source": ctx.payload["source"], "count": ctx.payload["count"]}
@app.task(
triggers=TriggerBuilder()
.on_event("feed_updated")
.with_args_from_event(_args_from_feed_event),
)
def ingest_feed(source: str, count: int) -> dict: ...
There is no separate broker for the event itself. The trigger backend is the event store. Argument providers must be module-level functions so the backend can serialize the reference — lambdas are not allowed and pynenc fails fast at registration if you try.
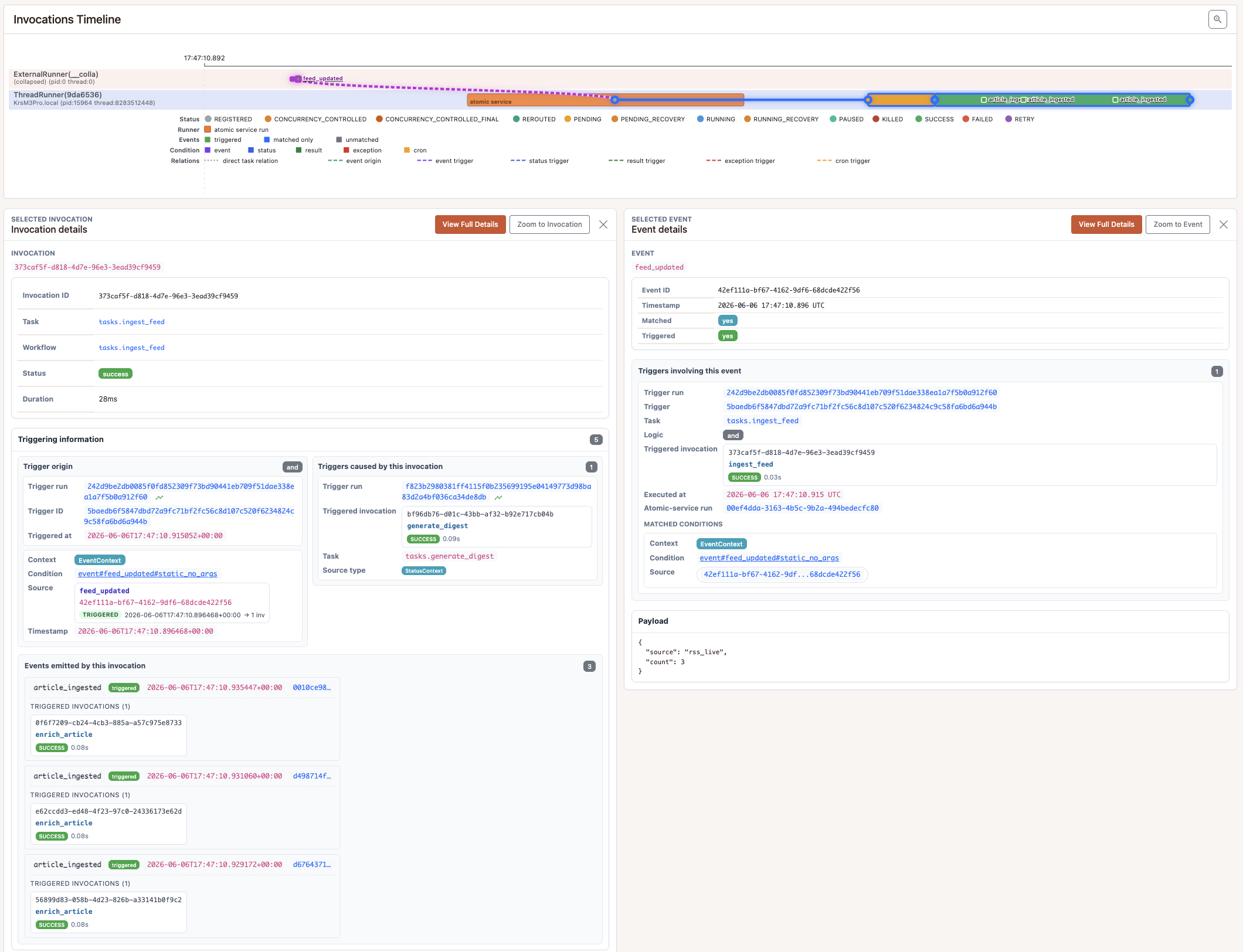
Here, enqueue.py emitted feed_updated. Pynmon places events emitted and invocations
registered directly from client code under an automatically assigned ExternalRunner;
it is an execution context, not an actual pynenc runner.
4. Pipeline composition with an argument filter
notify_subscribers chains on enrich_article SUCCESS, but only when the
upstream call had kind="breaking_news":
@app.task(
triggers=TriggerBuilder()
.on_status(
enrich_article,
statuses=[InvocationStatus.SUCCESS],
call_arguments={"kind": "breaking_news"},
)
.with_args_from_status(_args_from_enrich_status),
)
def notify_subscribers(article_id: str) -> str: ...
call_arguments is the argument filter on the upstream invocation; the
matching upstream call’s args are also what _args_from_enrich_status
projects into the downstream task’s signature. Same notify_subscribers for
every breaking-news article, no if kind == ... at the top of the function
and no .link(callback) at every call site.

5. Saga’s reactive leg — compensation on exception
@app.task(
triggers=TriggerBuilder()
.on_exception(enrich_article, exception_types="EnrichmentError")
.with_args_from_exception(_args_from_enrich_exception),
)
def alert_editorial(article_id: str, error: str) -> str: ...
When enrich_article raises EnrichmentError, alert_editorial runs with
the failing article’s id and the error string. The compensation lives next
to the compensating task, not buried inside the failing task or wired with
.link_error() at every call site.
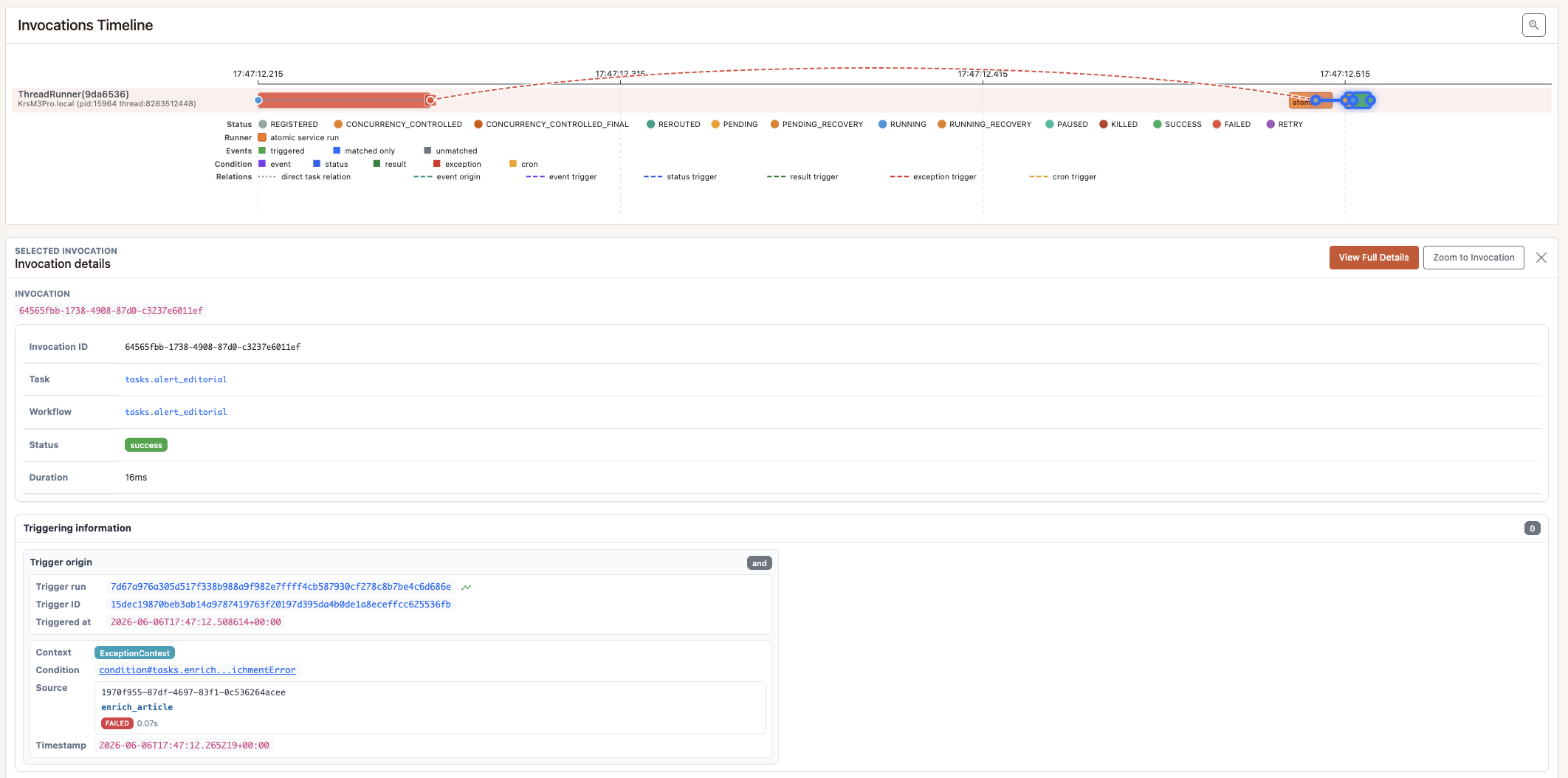
This is the reactive half of the Saga pattern. The transactional half — deterministic multi-step distributed transactions with resume-from-failure semantics across worker restarts — is what pynenc’s workflow system covers. That is a separate concern and a separate article.
6. Composite AND with heterogeneous conditions
generate_digest should run only when ingestion succeeded and produced
more than a threshold of articles:
DIGEST_THRESHOLD = 5
def _digest_threshold_filter(result: dict) -> bool:
return result.get("count", 0) > DIGEST_THRESHOLD
@app.task(
triggers=TriggerBuilder()
.on_status(ingest_feed, statuses=[InvocationStatus.SUCCESS])
.on_result(ingest_feed, filter_result=_digest_threshold_filter)
.with_logic("and"),
)
def generate_digest() -> str: ...
The two conditions are different kinds — a status condition and a result
filter — and they compose with a single with_logic("and"). Composite
predicates with mixed types are usually where the abstraction breaks down in
other systems and you fall back to writing a coordinator.
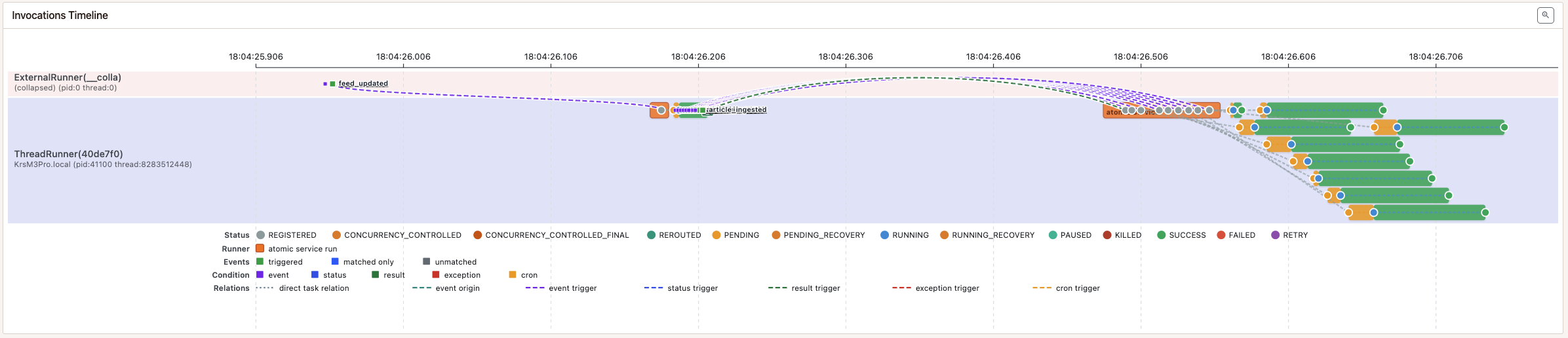
This timeline stays zoomed out to show the whole reaction. feed_updated
starts ingest_feed, which emits the events that fan out to enrich_article;
the same ingest_feed invocation also satisfies the status and result
conditions that start generate_digest.
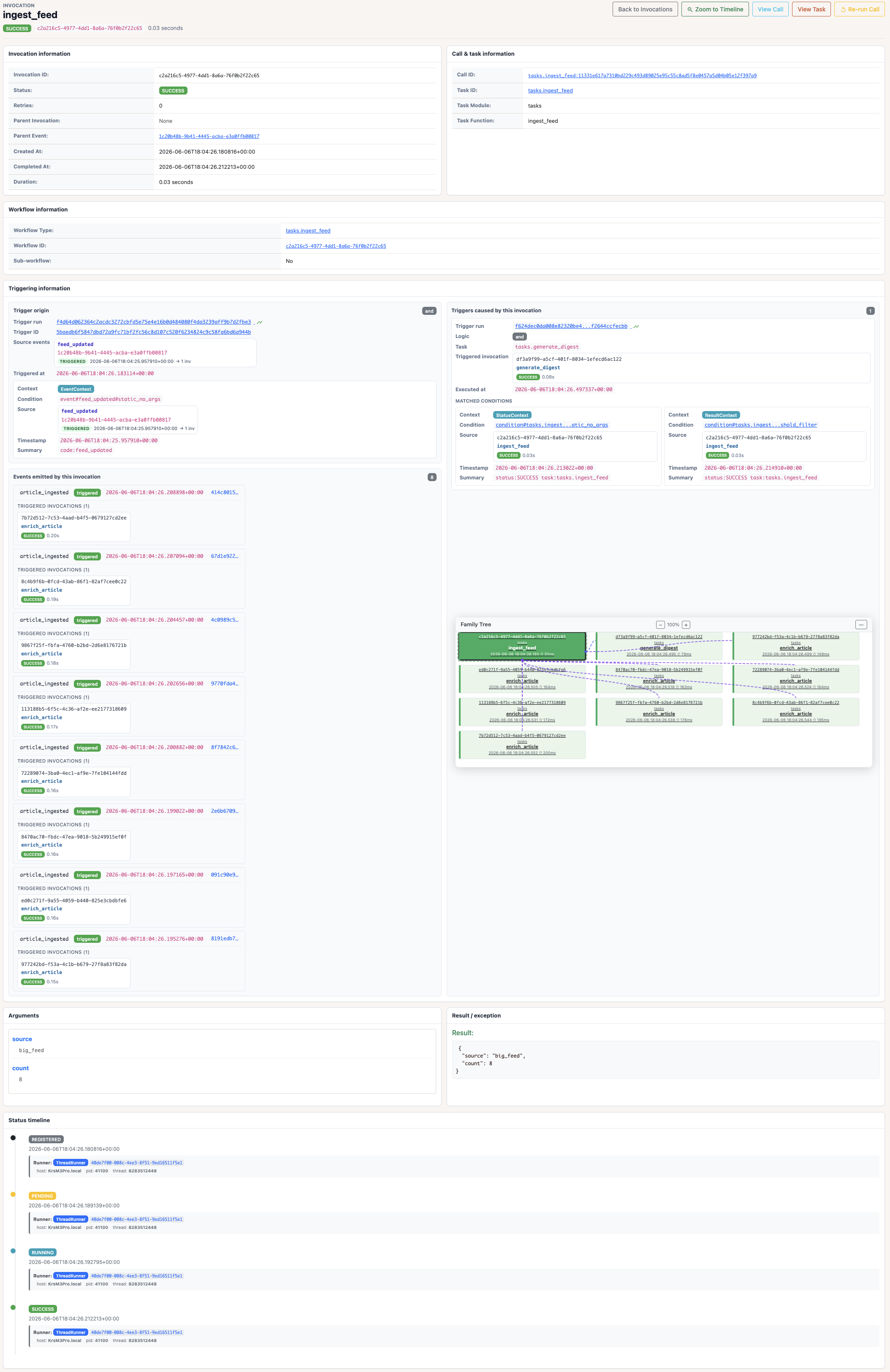
The focused invocation view shows that both conditions came from the same
ingest_feed invocation: one matched its SUCCESS status and the other
matched its result.
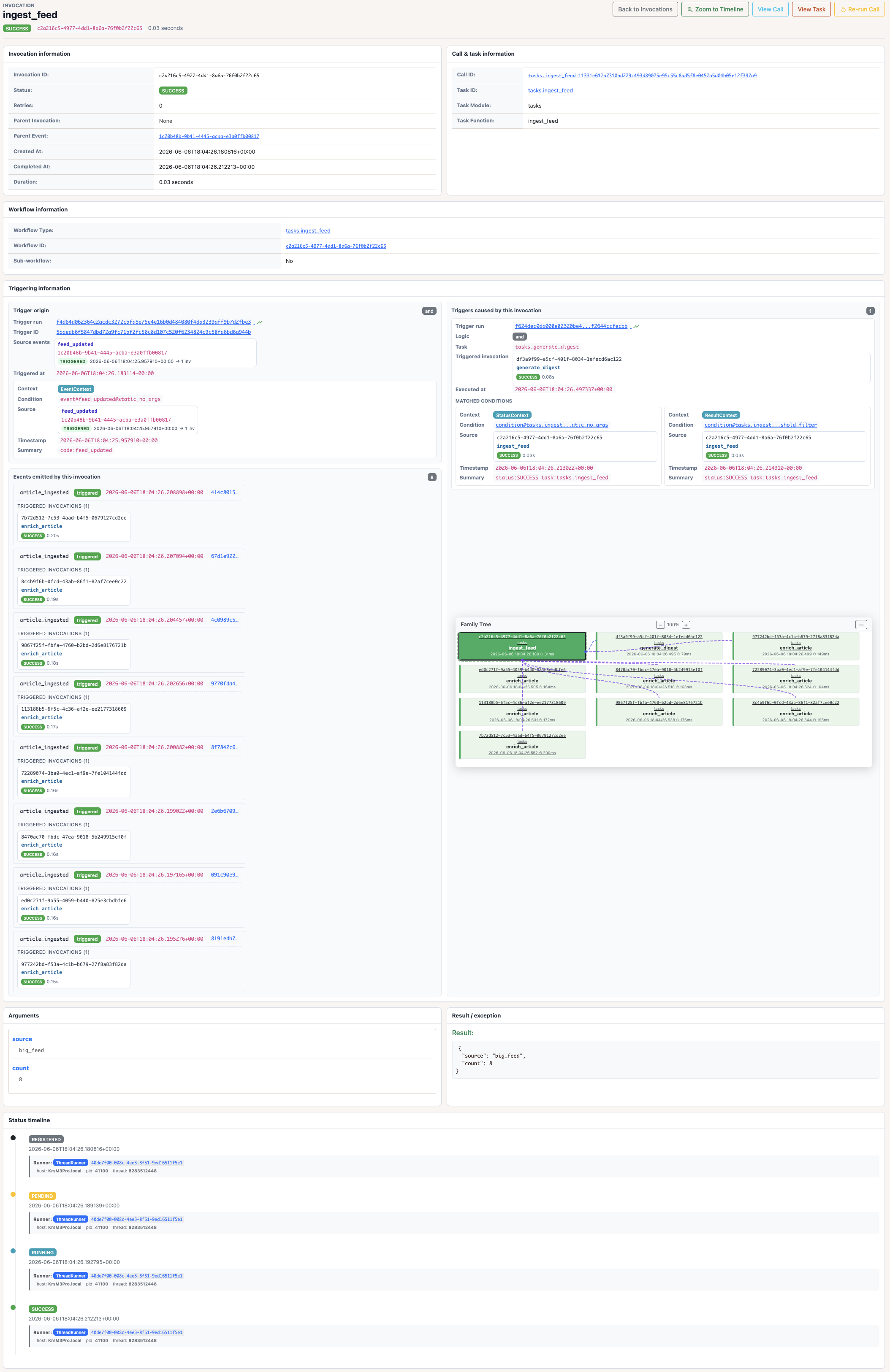
From the other side, the ingest_feed details connect the emitted article
events and show the composite trigger that created generate_digest.
How other Python frameworks usually handle these
| Concept | Celery | Dramatiq | Prefect | Airflow / OS cron |
|---|---|---|---|---|
| Polling vs. reactive | .link(callback) at call site |
pipeline(); conditions in task body |
on_completion hooks |
Per-operator hooks |
| Scheduled execution | Celery Beat (separate process) | None built in | schedule_interval per flow |
The DAG itself |
| Pub/sub | Use Redis Pub/Sub or Kafka externally | Same | Events + automations (paid SaaS) | Sensors |
| Pipeline composition | chain(a.s(), b.s()) at call time |
pipeline |
Inside a @flow function |
DAG >> operator |
| Exception compensation | .link_error() at call site |
In task body | on_failure hook |
Trigger rules per operator |
| Composite AND/OR | None native — needs a coordinator/Chord | None native | None native | Trigger rules approximate it |
Each of these tools makes its own tradeoffs. The point is not that any of them is wrong, but that their answer to the when question is different per concept. Pynenc keeps it as one declarative API on the reacting task.
Run the sample
git clone https://github.com/pynenc/samples
cd samples/trigger_demo
uv sync
uv run python sample.py
That spawns a worker subprocess, runs all six scenarios in order, prints a per-scenario report and a tail of the worker log, and tears everything down.
For a more interesting view, run it the manual way and add pynmon:
# Terminal 1 — worker (also runs the trigger scheduler)
uv run pynenc runner start
# Terminal 2 — fire scenarios or raw events
uv run python enqueue.py event_pubsub
uv run python enqueue.py compensation
uv run python events.py feed_updated --source rss_live --count 8
# Terminal 3 — UI
uv run pynenc monitor
The pynmon timeline is where the model gets concrete: tasks appear without anyone calling them, with the upstream invocation visible as the cause.
Monitoring with Pynmon
Pynmon connects emitted events, matched conditions, trigger runs, atomic services, and the invocations they create. The screenshots above use those views to keep each sample’s cause-and-effect chain visible; see the Pynmon monitoring guide for the full timeline, event, invocation, and runner views.
What the trigger system is not (yet)
- Not a deterministic multi-step transaction system. A trigger is a reaction; if the reacting task crashes, pynenc retries that task, but the chain across triggers is not a single transaction. For deterministic multi-step pipelines with resume-from-failure, see pynenc’s workflow system.
- No built-in event replay. Events fire and reach matching conditions once. Replay-on-restart is a separate concern.
- Conservative per-tick processing of fan-out. If a task emits many
events for the same downstream task in quick succession, the trigger loop
picks them up tick by tick rather than all at once. Pair with
running_concurrency=KEYS(per-account concurrency post) when downstream needs guarding.
Where this is useful
The trigger system is a fit when the when question is the part that makes your job hard:
- jobs that must run on a schedule and on a manual trigger
- pipelines where the next step depends on the previous step’s args or result, not just on its completion
- compensation paths that should live next to the compensating action, not inside the failing task
- composite gates where multiple heterogeneous conditions must all be true
The trigger system is not the tool for deterministic multi-step transactions across many tasks; that is a different abstraction and a different post.
Sample: https://github.com/pynenc/samples/tree/main/trigger_demo.